[Paper Review] Is Grep is all you need? How Agent Harnesses Reshape Agentic Search
논문리뷰 : https://arxiv.org/pdf/2605.15184
![[Paper Review] Is Grep is all you need? How Agent Harnesses Reshape Agentic Search](/ash-world/assets/is_grep_all_you_need_cover.png)
간만에 흥미로운 논문을 읽었다. 전반적으로 재미있는 내용이 많지만 특히나 인상깊은 글귀를 소개하고 시작하고자 한다.
Abstract에 바로 나오는데, 저자가 꼽은 실험 수행의 이유이기도 하다. ...including how tool out-puts are presented to the model and how performance changes when searches must cope with more irrelevant surrounding text, re-main under-explored in agent loops. ... 라는 부분이다.
번역하자면 도구 출력이 모델에 어떻게 제시되는지, 그리고 검색이 더 많은 관련 없는 주변 텍스트를 처리해야 할 때 성능이 어떻게 변하는지를 포함한 중요한 실질적 차원들은 에이전트 루프에서 충분히 탐구되지 않고 있습니다. 라고 할 수 있겠다.
절실하게 공감가는 부분이면서 한번 더 내가 취해야할 로드맵을 상기시켜주는 뜻깊은 문구인 것 같다.
이제 본격적으로 논문에 대한 이야기를 좀 해보자.
Abstract
해당 논문에서는 현재의 에이전트 시스템에 대한 아래 2가지 문제점으로부터 기안한다.
- 에이전트 시스템에서 RAG의 사용이 늘어나고 있음에도, 다양한 Retrieval 전략의 선택지가 agent architecture 및 tool calling 패러다임과 어떻게 상호작용하는지에 대한 체계적인 비교가 부족하다.
- tool calling이 모델에 어떻게 제시되는지, 그리고 Retrieval이 더 많은 관련 없는 주변 텍스트를 처리해야 할 때 성능이 어떻게 변하는지를 포함한 중요한 실질적인 연구들은 agent loop에서 충분히 탐구되지 않고 있다.
따라서 2가지 실험을 기획하고 수행한 empirical study 결과를 제시한다.
- 사용자 지정 에이전트 하네스(= 여기서는 Chronos라는 걸 쓰더군요.)와 Provider CLI 하네스(e.g. Claude Code, Codex, Gemini CLI)를 사용하여 LongMemEval의 116개 질문 샘플에 대해 grep과 벡터 검색을 비교하며, 인라인 도구 결과와 모델이 별도로 읽는 파일 기반 도구 결과 모두에 대해 수행
- grep 전용 및 벡터 전용 검색을 비교하면서 추가적인 관련 없는 대화 기록을 점진적으로 혼합하여 각 쿼리가 중요한 구절과 함께 더 많은 방해되는 자료에 포함되도록 함
1. Introduction
- 현대의 LLM Agent는 추론 시 외부 지식에 접근하기 위해 RAG에 점점 더 의존하는데 tool calling을 통해 agent는 검색 쿼리를 발행, 순위가 매겨진 결과를 수신, 답변을 생성하기 전에 반복적으로 이해를 개선한다.
- 그러나 Retrieval 전략이 agent architecture 및 tool calling 패러다임과 종단 간 에이전트 수행플로우에서 어떤 상호작용을 하는지는 잘 이해되지 않는다.
- 또한 기존의 연구들은 Retrival 전략을 agent architecture와 거의 분리하여 평가하기때문에 적합하지 않다.
- 가장 보편적인 Provider CLI Harness (e.g. Claude Code, Codex)의 경우
grep과 같은 명령줄 실행 도구에 모델이 직접 액세스할 수 있는 shell 기반 인터페이스에 도구 호출을 임베딩하는 반면, 사용자 정의 하네스와 에이전트 SDK는 도구 호출 루프, 컨텍스트 구성 및 결과 형식 지정에 대한 세분화된 제어옵션을 제공한다. - Retrieval Quality는 robustness of corpus noise에 직결되며 corpus noise가 증가함에 따라 Retrieval Strategy는 다른 속도로 저하될 수 있다.
- 따라서, tool calling을 기본으로 사용하는 현대의 LLM Agent를 위한 Retrieval Strategy에 대한 경험적 연구로 이러한 격차를 해소하는 것을 목표로 하며 세부 내용은 다음과 같다.
- LongMemEval 벤치마크의 116개 질문 하위 집합에 대해 여러 LLM을 평가하며, 이는 6가지 정보 검색 작업 범주에 대한 평가를 수행한다.
- 아래 3가지 관점의 기여점을 가진다.
- Retrieval, harness, and presentation : 어휘 검색과 밀집 검색 간의 선택이 에이전트 오케스트레이션 계층과 도구 출력이 인라인으로 표시되는지 또는 파일을 통해 표시되는지와 어떻게 결합되는지? 검색, 오케스트레이션 및 표현. 렉시컬 검색과 밀집 검색 간의 선택이 에이전트 오케스트레이션 계층과 결합되는 방식에 따라 어떻게 변화하는지?, 그리고 도구 출력이 인라인으로 표시되는지 또는 파일을 통해 표시되는지?
- Noise and Scale : corpus noise가 증가함에 따라 종단 간 동작이 어떻게 진화하는지?, 검색기 동작과 더 넓은 에이전트 루프 간의 상호 작용은 어떻게 변화하는지?
- Heterogeneity across agent stacks : 기본 텍스트 코퍼스가 고정되어 있더라도 아키텍처적으로 구별되는 오케스트레이션(사용자 정의 vs provider CLI)에 걸쳐 검색 효과성이 과연 안정적이지 않은지?
2. Overview of Retrieval in Agentic Systems
에이전트 시스템에서의 검색은 LLM 에이전트가 사용자 쿼리에 응답하기 위해 코퍼스에 대한 검색 작업을 식별, 실행 및 소비하는 프로세스를 의미한다. 과거의 방식인 고정된 쿼리로 하여금 문서 인덱스와 일치하고 상위-𝑘개의 결과가 프롬프트에 연결되는 독립 실행형 검색 파이프라인과 달리 에이전트 주도적으로 모델은 무엇을 검색할지, 몇 개의 쿼리를 발행할지, 검색 결과가 충분한지 또는 개선이 필요한지를 결정한다. 다만, 그 세부과정에섣 검색전략은 과거와 동일한 3가지 카테고리를 가져간다. Lexical, Semantic, Hybrid 검색이 이에 해당하고, 세부내용은 생략하겠다.
Agent Orchestration은 프롬프트를 구성하고, tool calling 결과를 dispatch하고, result를 response하고, iteration을 계속 진행할지 또는 최종 답변을 생성할지 결정하는 도구 호출 루프를 관리하는 환경 계층이다. 이경우 크게 2가지가 존재하는데, 1. Custom Harness, 2. Provider-Native CLI Harness 이다.
- Custom Harness
- 시스템 프롬프트, 도구 정의, 컨텍스트 구성, 결과 형식 지정 및 반복 종료 기준을 포함하여 에이전트 루프의 모든 단계에 대한 세밀한 제어를 제공함
- 가장 보편적으로 ReAct 패러다임을 적용한다.
- 개발자 의도에 따라 명시적인 context 관리를 허용한다.
- 매우 큰 개발 오버헤드(프롬프트 엔지니어링, 도구 인터페이스 설계, 컨텍스트 관리 등)가 단점.
- Provider-Native CLI Harness
- 모델이 직접 시스템에 접근할 수 있는 Shell 기반 인터페이스에 도구 호출이 포함된다.
- 에이전트는 grep, find, cat 및 기타 Unix 도구를 포함한 임의의 bash 명령을 네이티브 도구 작업으로 실행할 수 있다.
- 제공업체의 내부 구현에 따라 컨텍스트 구성 및 반복 제어를 관리하며, 이는 사용자에게 대부분 불투명한 것이 단점.
여기서 주목할 점은, 아래와 같다.
grep이 native bash 도구로 사용 가능할 때 “Retrieval Strategy”와 “Agent Ability” 사이 경계가 모호해진다는 것이다.
agent는 미리 정의된 검색 API에 국한되지 않고, 검색어, 플래그, 파일 대상을 동적으로 선택하여 자체 grep 명령을 구성할 수 있다.
하네스 선택과 별개로, tool calling architecture는 검색이후 검색 결과가 모델에 어떻게 전달되는지를 결정한다. 이는 context window 활용과 agent가 대규모 결과 세트를 처리하는 능력에 상당한 영향을 주고 실질적으로 context engineering에 따라 결정된다. tool callin garchitecture도 크게 2가지로 분류할 수 있다.
- Inline
- 검색 결과가 도구 응답 메시지로 직접 반환되어 대화 컨텍스트에 추가되는 방식을 뜻한다.
- 모델은 전체 결과 세트를 컨텍스트 창 내에서 수신하고 즉시 이를 기반으로 추론할 수 있으며 보편적으로 해당방식을 택한다.
- 에이전트의 장기 수행 관점에서는 시스템 프롬프트, 대화 기록 및 이전 도구 결과와 함께 context window의 공간을 놓고 경쟁하기 때문에 context rot을 유발하여 성능에 영향을 주기도 한다.
- Programmatic
- 검색 결과가 디스크에 기록되고 모델은 파일 경로 또는 요약 포인터만 수신한다.
- 에이전트는 결과를 액세스하기 위해 명시적인 작업을 수행해야 하며, 이는 검색 작업(예: 결과 파일에 대한 grep) 또는 전체 읽기(예: cat, read_file)와 같은 행위가 해당될 수 있다.
- inline 방식과 달리 context window의 경쟁점유로 인한 성능저하 문제는 없으나, 이를 대신하여 빈번한 tool calling이 진행된다.
3. Methodology
3.1. 작업 및 데이터셋
- LongMemEval 벤치마크의 116개 질문에 대한 대표적인 하위 집합을 평가하는 벤치마크이다.
- 에이전트가 여러 세션에 걸친 긴 대화에 대한 질문에 답변하는 능력을 테스트하고 각 질문에는 특정 유형의 세션이 동반된다.
- 올바르게 답변하는 데 필요한 정보가 포함된 세션 n개 이상과 쿼리와 관련 없는 가변 수의 방해 세션이 포함되어 있다.
- 질문은 여섯 가지 범주로 나뉩니다.
- knowledgeupdate(시간 경과에 따른 상태 변경 추적)
- multi-session(세션 간 정보 집계)
- single-session-assistant(모델 생성 콘텐츠 기억)
- single-session-preference(사용자 개인 선호도)
- single-session-user(사용자 명시적 사실)
- temporalreasoning(기간 계산, 이벤트 순서 지정 및 날짜 해결)
- 모든 대화 턴과 추출된 시간 이벤트는 로컬에 저장되며, grep 및 벡터 검색 모두에 대한 코퍼스로 사용함.
3.2 Agent Harness
Chronos 와 Provider-Native CLI Harness를 비교함.
3.3 LLM model
크게 5가지 모델을 사용함. Claude Opus 4.6, Claude Haiku 4.5, GPT-5.4, Gemini 3.1 Pro, Gemini 3.1 Flash-Lite
3.4 평가
- 기본적으로 LongMemEval 벤치마크 논문에 명시된 평가 프로토콜에 따라, 우리는 보조 LLM 평가기를 사용하여 각 모델 가설을 평가한다.
- 우리는 GPT-4o를 Metric Model로 인스턴스화했다 :
- 각 질문에 대해 평가기는 질문 텍스트, 참조 답변 필드, 그리고 에이전트의 가설을 수신하며, 범주 조건부 지침(예: 오프바이원 시간 계산에 대한 허용 오차, 선호도 항목에 대한 루브릭 스타일 채점, _abs 변형에 대한 기권 처리) 하에 binary classification을 출력해야 합니다.
- 우리는 평가기가 긍정적으로 응답한 질문의 비율로 정확도를 보고합니다.
- 채점 모델, 프롬프트 템플릿, 디코딩 설정을 조건 간에 고정함으로써, 하네스, 검색 모드, 세션 제한 설정 간의 차이가 평가 노이즈가 아닌 에이전트 파이프라인의 변화를 반영하도록 보장합니다.
4. Experiments
4.1 Experiment 1: Retrieval Mode, Harness, and Tool Calling Method
- Retrieval Mode(grep-only 대 vector-only), Agent Harness(Chronos vs Claude Code vs Codex vs Gemini CLI), 그리고 도구 호출 방법(인라인 대 프로그래밍 방식 파일 기반)이 전체 질문별 haystack이 노출될 때 종단 간 장기 기억 QA 정확도에 어떻게 공동으로 영향을 미치는지 분리한다.
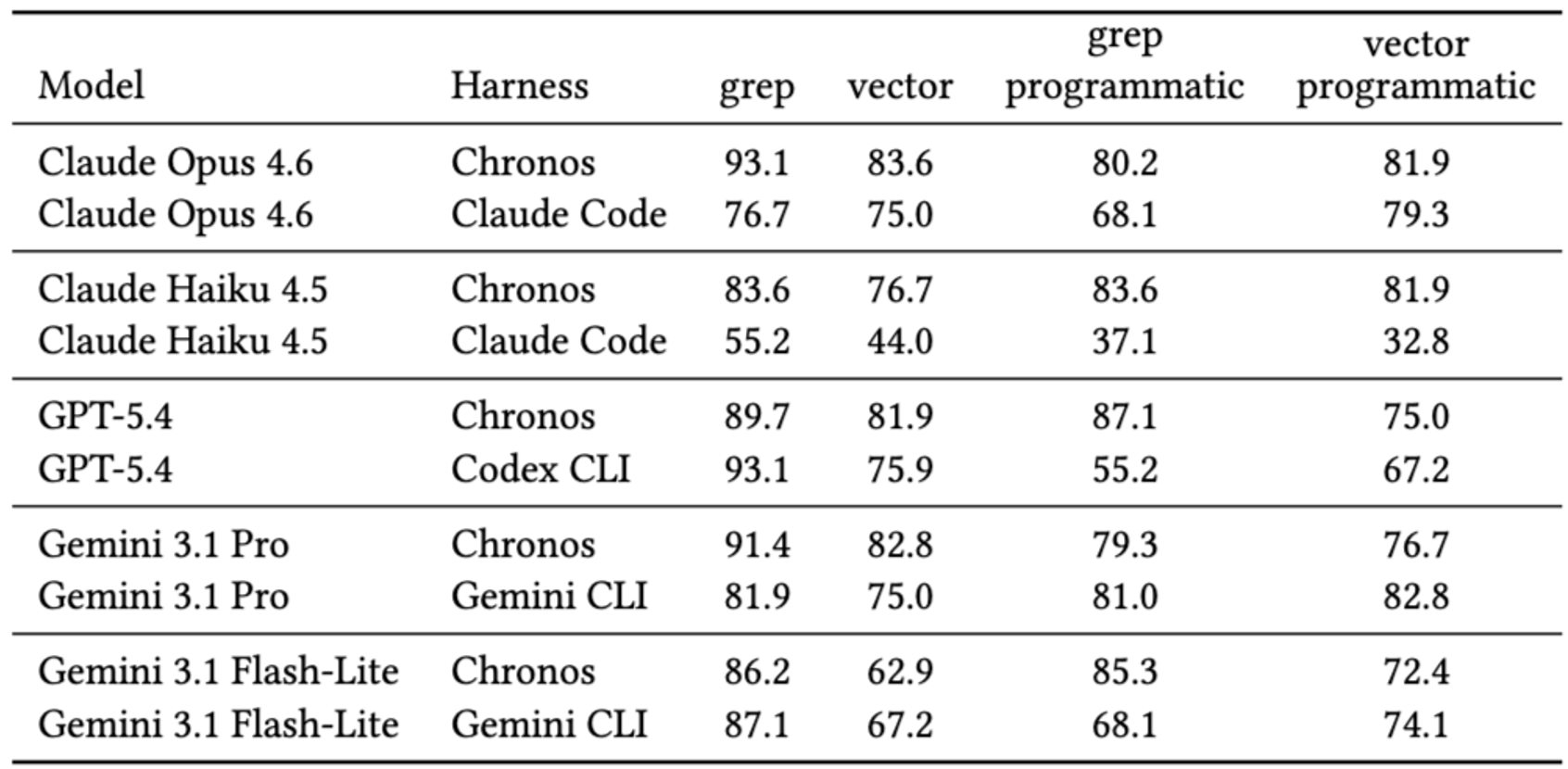
- LongMemEval은 문자 그대로의 증거를 복구하는 것을 정답으로 처리한다: 정확한 날짜, 수량, 선호도, 그리고 종종 토큰화 하에서 안정적으로 유지되는 구문이 이에 해당하는데, 어휘 도구는 임베딩 병목 현상 없이 해당 문자열을 표면화하며, 이는 표 1에서 인라인 grep이 강력한 기본값인 이유가 여기에서 나타타는 것이다.
- “Retrieval Mode”는 독립적으로 측정되지 않는다: 하네스는 시스템 프롬프트, 도구 설명, 그리고 결과가 채팅으로 어떻게 렌더링되는지를 형성하며, 이 모든 것이 모델이 쿼리를 예약하고 언제 중지할지를 결정하는 방식에 영향을 미친다.
4.2 Experiment 2 : Context Scaling with Increasing Noise
- 모델이 동일한 질문별 번들에서 더 많은 세션에 노출될 때 어휘 및 밀집 검색이 어떻게 달라지는지 추이를 본다.
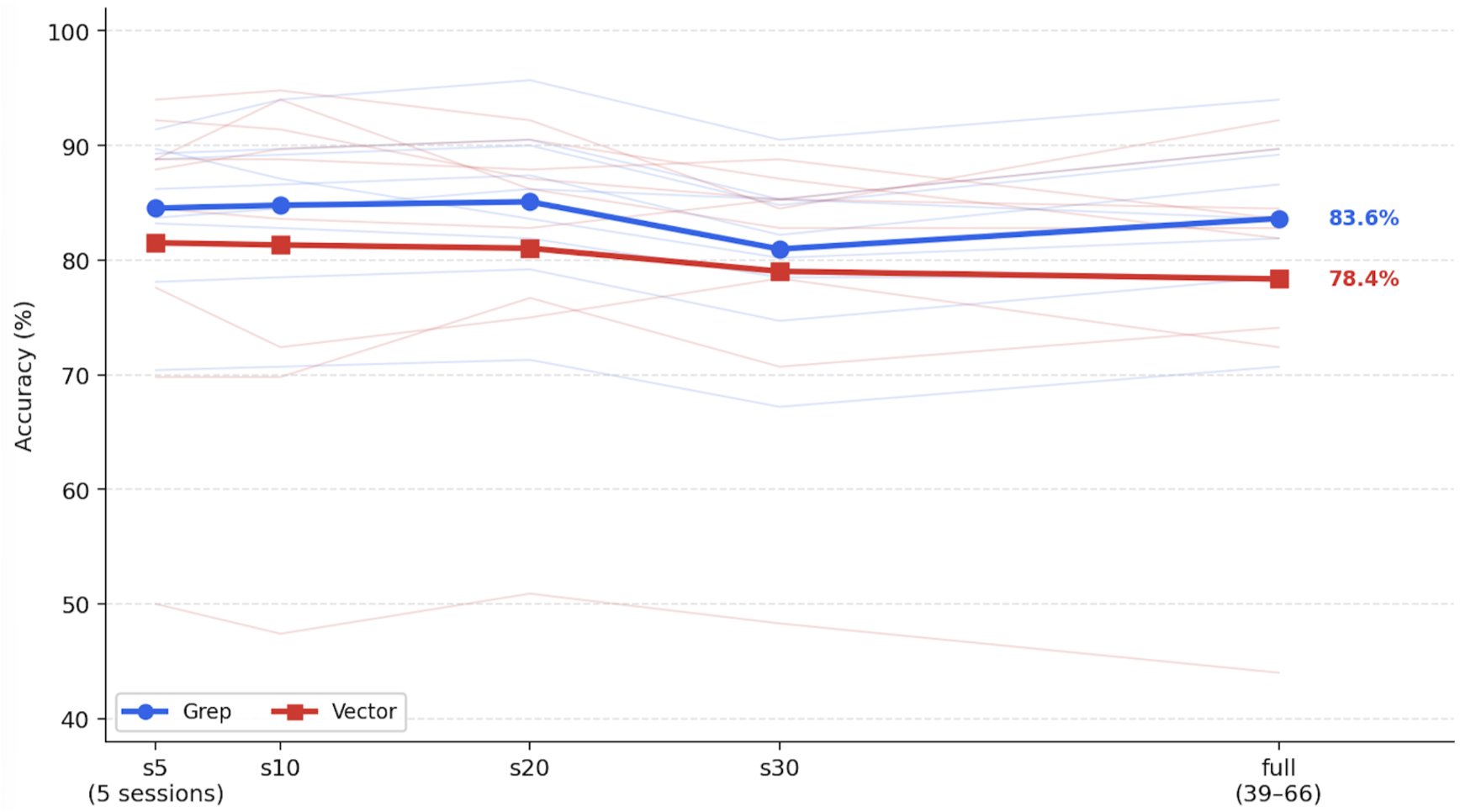
- 일반적인 실무자 직관은 lexical search는 작은 코퍼스에서는 충분하지만 규모가 커지면 실패하며, 더 표현력이 풍부한 semantic search가 코퍼스 크기가 증가함에 따라 필요해지며 이는 부분적으로 동의한다. 왜냐하면 코퍼스 크기뿐만 아니라 하네스와 백본에 따라 달라진다는 것을 실험에 의해 보여지고 있기 때문이다.
5. Limitations
- 개념적으로, 저희의 결론은 장기 기억 대화형 QA에 국한된다.
- 질문은 다중 세션 채팅, 명시적인 시간 표현, 개인/사용자 사실에먼 근거한다.
- 어휘 도구는 답변이 종종 원문 그대로에 의존하기 때문에 여기서 불균형적으로 적용될 수 있다. 증거가 거의 문자 그대로이지 않은 도메인(예: 요약된 초록에 대한 과학적 합성, 시각 중심 문서 또는 코드 의미론)에서는 다르게 나타날 수 있다.
- grep이 일반적으로 벡터를 “능가한다”고 주장하는 것이 아닌 연구 대상이 되는 작업 분포 및 코퍼스 하에서 종단 간으로 승리할 수 있다는 것만을 주장한다.
6. Conclusion
Chronos와 Provider CLI 전반에 걸쳐, grep은 해당 연구에서 벡터 검색보다 일관되게 더 높은 정확도를 보이며, 평가하는 모든 하네스-모델 쌍에 대해 인라인 grep이 인라인 벡터보다 우수한 결과를 보인다. 동시에, 전체 점수는 어떤 하네스와 도구 호출 스타일이 사용되는지에 따라 크게 달라지며, 근본적인 대화 데이터가 동일하더라도 파일 기반 전달 및 제공업체 CLI 셸은 코퍼스 변경 없이도 어휘적 이점을 반전시키거나 제거할 수 있다.
👍 My Insight
agent가 장기 실행을 하는 관점에서 다양한 tool과 결과를 가져오는 것은 이제는 당연시 여기는 부분이다. 단, 저자들도 지적했듯 그러한 과정의 이면 속 호출의 결과를 담는 context에 대한 optimization, efficiency performance 등의 연구는 충분히 이루어지지 않고 있다. Harness가 만연해지는 시대에 이러한 성능 평가 및 부분적 성능에 대한 고찰이 없다면 정말 말로만 하던 AI의 노예와 다를바 없어질 것이라는 의견이다.
한편, 저자들의 평가방식은 인상깊다.
필자도 agent의 evaluation에 대한 고민을 많이 하고 있는데, Back-bone LLM, Harness Architecture를 서로 다른 변인으로 두고 평가하는 방식은 올바른 방향이라고 생각된다.
다만, 조금 더 atomic한 단위로 바라보는게 과정이 복잡할지언정 정말 올바른 평가가 잘 될 것이라는 생각이다.
개인적으로 LLM-as-a-Judge를 불신하는 편인데 단순 llm이라면 단연코 지적했을 것이다. 다만 agent / harness로 넘어온 순간부터 그것을 신뢰도 없다고 판단할 수 있는가? 에 대한 깊은 고찰이 필요한 것 같다. (개인적으로는 평가의 환경과 대상이 달라졌기 때문이라고 생각한다.)