Definition of Harness Engineering
하네스, 하네스 엔지니어링이라고 많이 말하지만 정작 이게 뭐야? 라고하면 어떻게 얘기해야 할까?

A. Harness의 기원
가장 먼저 Harness라는 키워드를 사용한 사람은 누구일까?
조사해보니 Hashicorp & Terraform의 창립자인 Mitchell Hashimoto가 26년 2월 초 Harness라는 용어를 사용하였고 이때 당시엔 "에이전트가 실수할 때마다 다음엔 더 잘하길 바라지 말고, 다시는 그 실수를 못 하도록 환경을 엔지니어링하라”는 프레이밍과 같이 대두되었다. 다만, 다양한 커뮤니티에서 Harness와 같은 맥락의 개념은 오고갔으며, 명확하게 자리잡은 것이 26년 2월초인 것이다.
그렇다면, Harness System은 무엇일까? 이를 정의하기 위해서는 과거의 변천사를 먼저 살펴볼 필요가 있다.
과거에는 LLM Model의 높은 성능이 주목받았고, 그 후 짧게 지식의 실시간성을 보완할 RAG가 주목받았다. 이후 빠르게 동적으로 실행되는 Agent가 수면위로 올라오며 26년 4월 현재 Agent를 다루는 전체적인 인프라 시스템인 Harness System이 가장 주목받는 것이다.
즉, bottom-up의 방향을 따라간다고 볼 수 있으며 현재의 Harness System은 암묵적으로 Agent를 기반으로 하는 Harness System을 의미하며, 그 정의는 아래와 같이 정의할 수 있겠다.
Harness = Model 그 자체를 제외한, Agent를 둘러싼 모든 환경조금 더 풀어서 말하면, 모델의 추론 능력을 실제 production 환경에서 신뢰성 있게, 반복 가능하게, 안전하게 동작하도록 만드는 환경, 제약, 피드백 루프의 집합이다.
Model의 출력을 “제어하기 어려운 말”에 비유한다면, Harness(=굴레, 고삐)라는 표현과 같이 말을 사용자가 원하는 방향, 의도대로 제어하는 방법에 해당하는 것이다.
이는 단순히 Skills, Hook을 사용한다는 작은단위의 행동이 아닌 상위 개념에 더 부합하는 것이다.
B. Harness Engineering이란?
A Section에서 우리는 Harness를 아래와 같이 정의하였다.
Harness란, LLM Model 그 자체를 제외하고 Agent를 둘러싼 모든 환경
그렇다면, Harness Engineering은 어떤 작업을 의미하는 것일까?
26년 4월 2일에 martinfowler에 작성된 Birgitta의 포스트에서는 Harness라는 컨셉 자체가 매우 광범위하며, 다양한 Agent 중 Coding Agents에 국한된 내용을 기술하고자 한다. 잘 설계된 Coding Agent 기반 Harness는 크게 2가지의 목표를 달성한다.
- 에이전트가 처음부터 올바른 결과를 얻을 확률을 높이는 것
- 문제가 사람의 눈에 띄기 전에 최대한 많은 문제를 자체적으로 수정하는 피드백 루프를 제공하는 것이다.
궁극적으로 이는 검토 작업량을 줄이고 시스템 품질을 향상시키며, 그 과정에서 토큰 낭비를 줄이는 부가적인 이점을 제공하게 된다.
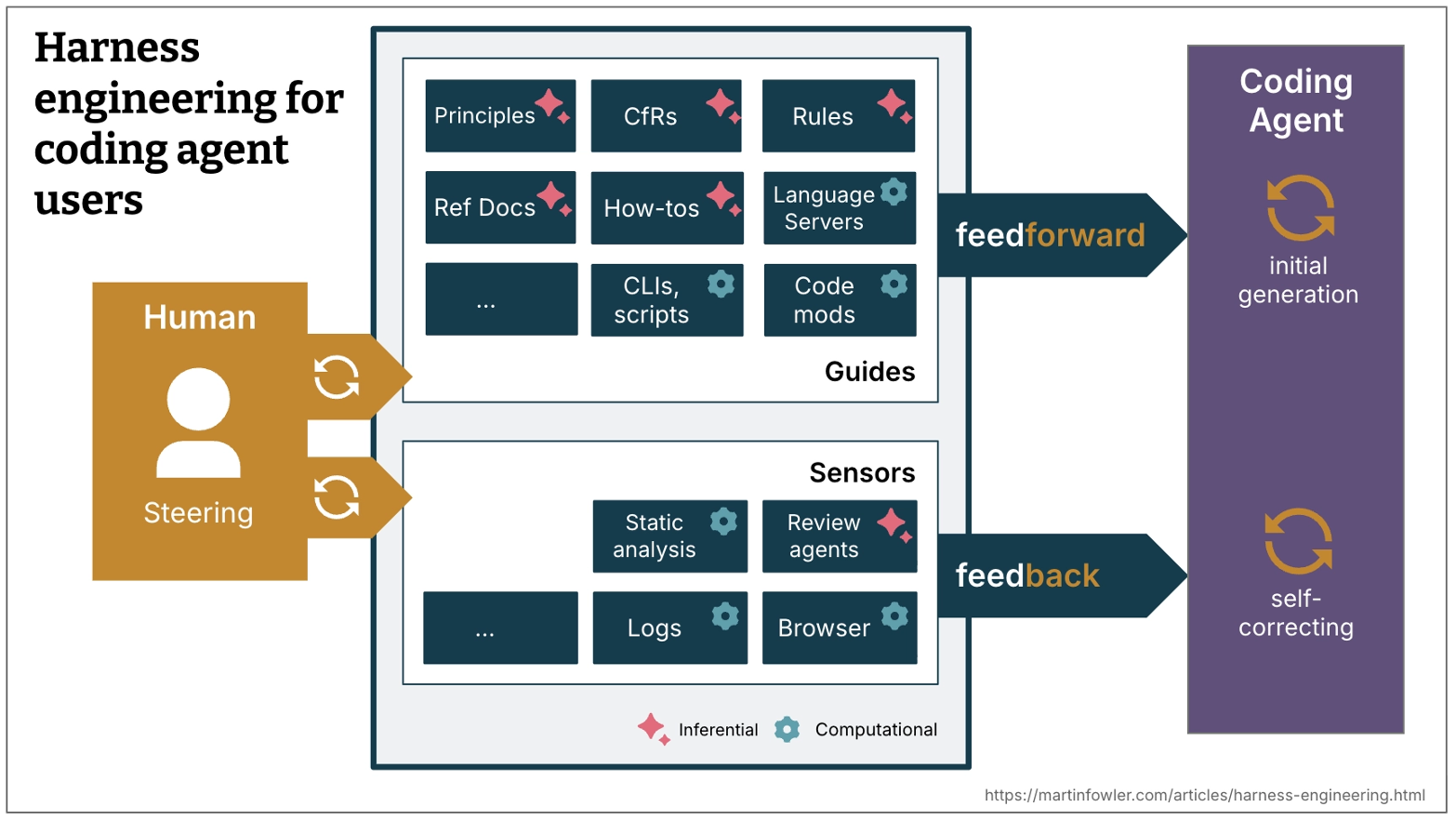
다양한 개념이 하나의 figure에 서술되어 있는데, 청록색 box와 같이 Agent가 수행하게 될 최소단위의 행동을 Components라 지칭하겠다. 저자는 해당 그림에서 Harness의 구성요소를 범주화하였는데, 그 내용이 아래와 같다.
- Agent의 실행 시점 기준의 분류 : 주체가 Coding Agent
- FeedForward : coding agent의 직접적인 실행(Execution) 전 확인하게 되는 components를 의미한다. 즉, Components에서 Agents의 순방향을 가진 행위를 의미한다.
- FeedBack : coding agent의 직접적인 실행(Execution) 후 확인하게 되는 components를 의미한다. 즉, Agents에서 Components의 역방향을 가진 행위를 의미한다.
- Components가 사용되는 시점에 따른 분류 : 주체가 Components
- Guides : FeedForward를 제어하는 전체집합입니다. 에이전트의 행동을 예측하고 행동하기 전에 에이전트를 유도하는 것을 목표로 합니다. 가이드를 사용하면 에이전트가 첫 시도에서 좋은 결과를 낼 확률이 높아집니다.
- Sensors : FeedBack을 제어하는 전체집합입니다. 에이전트의 동작 후를 관찰 하고 자체 수정을 지원합니다. 특히 LLM(로컬 라이프사이클 관리)에서 사용하기에 최적화된 신호, 예를 들어 자체 수정 지침이 포함된 사용자 지정 린터 메시지 등을 생성할 때 매우 효과적입니다. 이는 일종의 프롬프트 주입 방식입니다
- Characteristic of implementation(= 구현방식에 따른 특징)에 의한 기준분류 : 주체가 Components
- Computational : 결정론적이고 빠르며 CPU에서 실행됩니다. 테스트, 린터, 타입 검사기, 구조 분석 기능을 제공합니다. 실행 시간은 밀리초에서 초 단위이며 결과는 신뢰할 수 있습니다.
- Inferential : 의미 분석, AI 기반 코드 검토, “LLM을 심사위원으로 활용”. 일반적으로 GPU 또는 NPU에서 실행됩니다. 속도가 느리고 비용이 많이 들며, 결과가 비결정적입니다.
그에 대한 구현예시는 다음과 같다.
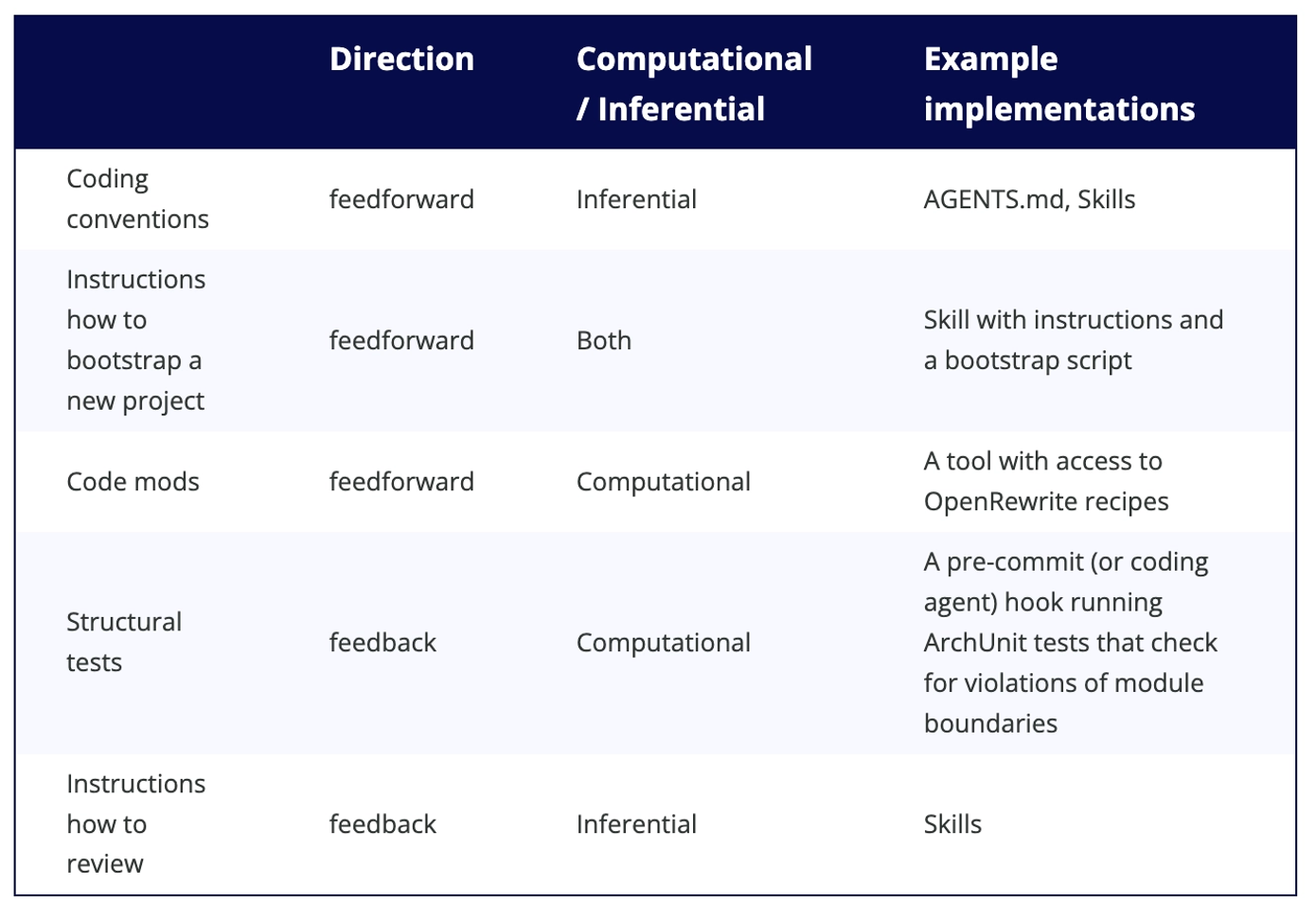
위 자료를 포함하여 개인적으로 찾아본 다양한 레퍼런스를 참고한 결과 Harness라는 개념은 매우 광범위한데, 우리는 Coding Agents 기반의 Harness와 General한 Harness를 동일시하고 있다는 것이다.(아마 가장 보편화된 사례가 Claude Code이기 때문에 그러지 않을까 싶다.) 이는 개념의 모호성을 스스로 증가시키고 있는 것이며, 명확한 구분을 할 필요가 있다.
C. Harness Engineering의 접근법
따라서, Fundamental한 Harness Engineering에 접근하고자 한다면 Coding Agent의 형상에서 벗어나 더 깊게 구체화한 approach가 필요하다.
이에 따라 아래의 5-Layer Harness Approach 제안한다.
- 1-Layer : Architecture
- 2-Layer : Identity & Guardrail
- 3-Layer : Task Ability
- 4-Layer : Context Strategy
- 5-Layer : Stability & Observility
각 Layer 단계에 대하여 설명해보겠다.
1-Layer : Architecture
첫번째, 아키텍쳐 레이어이다. 결국 우리가 Agent라 부르는 것들은 LLM Model의 의존성을 띄기 마련인데 꼭 LLM이 하나일 필요는 없다고 생각한다. 현재 대중화된 agent system들(= Codex, Claude Code)은 대부분 기존의 SAS(= Single Agent System)에 지나지 않는 아키텍쳐적 구조를 가진다 sub-agent를 활용하는 것 역시 동일 llm의 별도 session을 만들어내는것이 대부분이다.(물론 몇몇 framework는 그렇지 않은 경우도 존재한다. e.g. Moltbot의 경우 이와는 조금 다른 방식이다.) 즉, MAS(= Multi Agent System)의 구조가 얼마든지 적용될 가능성이 있음에도 불구하고 appliance 하지 않는 현실이다. Architecture Layer는 이러한 단점을 보완하는 레이어이다. 보다 다양하고 자유로운 agent간, agent와 user간 통신구조를 가질 수 있을 것이다.
2-Layer : Identity & Guardrail
두번째 Identity & Guardrail 레이어이다. 아는사람을 알겠지만 Soul.md 라는 것을 들어본 적이 있을 것이다. 표현으로는 agent의 가치관과 정체성을 지닐 수 있다고 하나 실제로 살펴보면 과거 System Prompt에 Persona Prompting을 하던 것과 크게 다르지 않다. 단, Agent가 다수로 늘어날수록 더 유연한 R&R 분배와 수행 task의 멱등성을 살리기 위해 해당 layer는 별도로 필요하다는 생각이 들었다. 한편 Guardrail 역시 무시할 수 없다. Agent의, Harness의 본질은 결국 원하는대로 제어하는 것이다. Security의 문제는 산업계에서 크게 화두가 되는 부분으로 아무리 뛰어난 성능을 가졌다고 할지라도 이 부분이 해소되지 않는한 깊게 접목되기 어렵다. 가장 큰 실사례가 Nvidia의 Nemo-Claw이다. 이들 역시 policy 기반으로 보안적 위협을 방지했다고 하나 Dynamic한 적용이 되지 않는다. (= 일종의 Rule-base로 처리했다고 한다.) 가장 이상적인 부분은 사용자의 행동에 따라 공통된 Guarail은 적용하고, 사례에 기반하여 case-by-case로 판단해야하는 형상이라고 생각한다.
3-Layer : Task Ability
세번째 Task Ability 레이어이다. 이 부분은 가장 확장성이 넓은 레이어로 1-Layer에서 시스템 아키텍쳐적 제약이 없는 경우를 전제로 한다.
현재 사용하고 Skills, Hook은 기존 tool-calling과 MCP의 새로운 표현(사용)방식에 지나지 않는다. 그렇기 때문에 우리는 조금 더 뾰족한 부분으로의 performance를 들여다 볼 필요가 있는 것이다.
가령, agent의 기본 내장 tool 중 grep 이라는 툴이 있는데 Agent가 이 툴을 사용하는 것이 정말 성능적으로 유효한지? 와 같은 부분에 우리는 의문점을 가질 필요가 있다는 것이다.
이를 간접적으로 증명하듯 최근 이와 관련된 논문이 게재되게도 했다. : Is Grep All You Need? How Agent Harnesses Reshape Agentic Search
즉, agent의 동작은 의외로 세밀한 기계들의 조합시스템과 비슷하기 때문에 성능면에서의 고도화를 꾀할 부분이 상당히 많다.
4-Layer : Context Strategy
네번째 Context Strategy 레이어이다. 1-Layer에서 언급했듯 Agent와 Harness는 결국 LLM에 의존하게 된다. 그렇다면 빼놓을 수 없는 것이 Context 관리인데, 최근 LLM들이 Long-Context를 잘 처리한다고 하나 이것은 주장과 다르다. 실제로 처리할 수 있다는 것이지, 잘 처리하는것이 아니기 때문이다. 이는 경험적으로 Claude Code를 사용하는 실 사용자한테도 오래사용한 Session이 진행될 수록 처리능력이 떨어지는 것에서 간접적으로 볼 수 있으며 관련된 연구자료도 많다. 즉, Context를 관리하는 전략은 상당히 중요하며 이는 단순히 skill로 나누고 하는게 아닌 실제 llm에 주입되는 영역을 위주로 바라보아야 한다. 그렇기때문에 LTM/STM 의 관리와 Session별 내용을 관리할 수 있는 Summerization의 영역도 새롭게 다시 떠오르지 않을까 한다.
5-Layer : Stability & Observility
마지막 Stability & Observility 레이어이다. 이는 쉽게 말해 평가 레이어라고 말해도 무방하다. Agent의 동작이 올바르게 했는지 아닌지, 이를 어디부터 어디까지 관측(=tracing)할 것인지 이를 바탕으로 Agent 또는 Harness에게 어떤방식으로 feedback을 주어 반영할 것인지 등 흔히 얘기하는 개념인 Self-Evolving이 해당 레이어가 잘 구축되었을 때 파생될 것이라 생각한다.
Harness의 본질은 결국 사용자의 의도대로 제어하는 것이다.
각 레이어 단계들은 관련이 없어보이지만 실제로 5-layer의 구축이 결과론적으로 1-layer에 영향이 주기 마련이다.
즉, 순차적이지 않을 수 있어도 위의 5개 layer는 각각 상호영향을 주며 일종의 Life-Cycle을 그리게 되는 것이다.Conclusion
RAG, Agent, Harness에 이르기까지 우리는 너무나도 빠른 변화에 명확한 개념정의 및 이해없이 그저 보이는 모습에 입각하여 바라보고 있을지도 모른다. 그것만으로 괜찮을 수 있으나, 정말 대상에 대하여 잘 사용하려면 근원적인 이해가 필수적으로 동반되어야 한다고 믿는다. 현재 필자의 업무환경역시 말하는 바를 100% 충족시키지는 못하지만 그럼에도 불구하고 정확한 이해와 객관적인 비교사실을 바탕으로 명확하게 알아야 비로소 전문가라고 말할 수 있지 않을까 싶다.